
Nibble Sort
(8 February 2015)
A while back, John Regehr posted the Nibble Sort Programming Contest on his blog. The objective was to write a program that sorts the 4-bit components (nibbles) of 64-bit words as fast as possible. For example, 0x42badc0ffeed00d5 should result in 0xffeedddcba542000 after sorting.
Update (July 2015): Added analyses of the two winning solutions.
My Entry
Being susceptible to nerd sniping, this problem stuck in my head and I ended up spending two Saturday afternoons trying to implement a fast solution.
The first time, I set up my timing function wrong, and GCC optimized the whole thing away. It seemed as my solution was no faster than John's reference implementation, and I gave up. Lesson 1: check the assembly to see what's going on.
Unable to let go, I returned to the problem the next weekend, fixed the timing function, and ended up with this solution:
#include <stdint.h>
uint64_t nibble_sort_word(uint64_t arg)
{
const uint64_t ones = 0x1111111111111111ULL;
if (arg == (arg & 0xf) * ones) {
return arg;
}
uint64_t count = 0;
for (int i = 0; i < 16; i++) {
count += 1ULL << (4 * (arg & 0xf));
arg >>= 4;
}
uint64_t mask = ~0ULL;
uint64_t result = 0;
for (int i = 0; i < 16; i++) {
int n = count & 0xf;
count >>= 4;
result = (result & ~mask) | ((ones & mask) * i);
mask <<= 4 * n;
}
return result;
}
My first thoughts when reading the problem went to radix sort, since that's a good way of sorting numbers without comparisons. But in the problem at hand, the numbers are so small that the radix might as well cover the whole 4 bits, which turns the algorithm into counting sort. The idea is to count the number of occurrences of each value, and then simply lay out the right number of each value in order.
What got me excited was the idea of storing the counts packed into a 64-bit word: we could use four bits for each count, and the code to do the counting becomes very elegant:
uint64_t count = 0;
for (int i = 0; i < 16; i++) {
count += 1ULL << (4 * (arg & 0xf));
arg >>= 4;
}
If we think of count as an array of 4-bit values, the code is essentially doing count[arg & 0xf]++. The arg & 0xf expression gets us the least significant nibble in arg. We multiply that by 4 to get the bit index of the count for that nibble, shift a 1 into that position and add it to the count.
This works great, except that with 4 bits to hold the count of each nibble, we run into a problem if one nibble occurs 16 times, as in 0xeeeeeeeeeeeeeeee. The good news is that this kind of input is already sorted, but how do we detect it? The best I could come up with was:
const uint64_t ones = 0x1111111111111111ULL;
if (arg == (arg & 0xf) * ones) {
return arg;
}
I was quite pleased with this at the time. It didn't look like it added much overhead: the branch would be easy to predict (it's essentially never taken since the input distribution is uniform) and the multiplication didn't seem too bad. I later saw Jerome's winning non-SIMD solution which solves this more efficiently:
if ((word << 4 | word >> 60) == word)
return word;
The bit rotation will get compiled down to rolq $4, %rax, which is more efficient than multiplication.
The second part of the code uses the counts to build up a new, sorted, word which is the result. My first attempt looked like this:
for (i = 0xf; i >= 0x0; i--) {
n = ((count >> (4 * i)) & 0xf);
while (n--) {
result = (result << 4) | i;
}
}
For each nibble value (high to low), the code reads the count into n, and then shifts n nibbles of the current value into the result. It is straight-forward, but I didn't like the while-loop which has an unpredictable branch as the count varies a lot. Eventually, I came up with a branch-free solution:
uint64_t mask = ~0ULL;
uint64_t result = 0;
for (int i = 0; i < 16; i++) {
int n = count & 0xf;
count >>= 4;
result = (result & ~mask) | ((ones & mask) * i);
mask <<= 4 * n;
}
The idea is to use mask to keep track of the unfinished part of the word. For each nibble value i, we take the finished part of the word (result & ~mask) and or that with a mask of i-nibbles covering the unfinished part ((ones & mask) * i). Then we update the mask based on the count for i. Not as straight-forward, but faster.
Results
The results of the competition are in John's blog post. My solution did much better than I expected: it finished 12th in the non-SIMD category and runs 14x faster than the reference implementation.
Seeing Jerome's winning solution confirmed that I was on the right track with the counting sort. I wish I had stayed with the problem a little longer; the idea of doing table-lookups for the counting had entered my mind, but at that point I was out of time and didn't try it out. I also didn't have any ideas for constructing the result from the counts any faster, which is the slow part of my code.
The Winning Non-SIMD Solution
The winning non-SIMD solution is written by Jerome. Like mine, it is a counting sort with the counts packed into a 64-bit word. Unlike my solution, it uses lookup tables for most computations, and it has a clever approach for constructing the result from the counts.
Using lookup tables can be a good way of speeding up computation when the set of inputs and outputs is fairly small. For example, one of the population count algorithms in Hacker's Delight uses lookup tables. The idea is basically to replace the function f(x) with an array where arr[x] = f(x). If loading from the table is faster than computing the function (pretty likely if the table is in the L1 cache), it's a win.
For counting the number of nibbles of each value, Jerome uses a table with 256 entries: table[0xab] contains the value of the counts variable for nibbles 0xa and 0xb added together (that is, (1ULL << 0xa * 4) + (1ULL << 0xb * 4)). Computing counts for the 16 nibbles is done with 8 table lookups:
uint64_t counts = 0;
for (int i = 0; i < 8; i++)
counts += table[(word >> 8 * i) & 0xff];
The really clever part is how Jerome constructs the result from the nibble counts. My solution and many of the others build the result by or-ing masks together. For example, 0x4220 = 0x4000 | 0x0220 | 0x0000. Jerome, however, builds the result additively. For example, 0x4220 = 0x1110 + 0x1110 + 0x1000 + 0x1000. The beauty of this is that it's always a mask of 0x1s that's added to the result, only shifted some amount to the left, determined by the nibble counts, to avoid changing the "finished" nibbles.
How does this work? The idea is to keep adding 1s to the nibbles that aren't finished yet. We know how many are finished by adding the current count to the previous counts.
Jerome's code would process the nibble couts for 0x4220 from low to high. First, the number of 0x0-nibbles is one, so the number of finished nibbles is one and 0x1111 << 1 * 4 is added to the result. Next, the number of 0x1-nibbles is zero, so the number of finished nibbles is 0 + 1 (0 for the current nibble, 1 for the previous nibbles), and 0x1111 << (0 + 1) * 4 is added to the result. Moving on, there are 2 0x2-nibbles, so now 2 + 1 nibbles are finished, and 0x1111 << (2 + 1) * 4 is added to the result. There are no 0x3-nibbles, so 0x1111 << (0 + 3) * 4 is added to the result. Finally, there is 1 0x4-nibble, so 0x1111 << (1 + 3) * 4 is added to the result and we are done. In code, this can be expressed as:
uint64_t result = 0;
int previous_counts = 0;
for (int i = 0; i < 16; i++) {
int count = (counts >> (i * 4)) & 0xf;
result += (n + previous_counts >= 16) ? 0 :
(0x1111111111111111 << (count + previous_counts) * 4);
previous_counts += count;
}
A conditional expression has been added to avoid undefined behaviour by shifting too much to the left. This code works nicely, but Jerome now takes it further by processing two counts at the time:
uint64_t result = 0;
int previous_counts = 0;
for (int i = 0; i < 8; i++) {
char count_byte = (counts >> (i * 8)) & 0xff;
int count1 = count_byte & 0xf;
int count2 = (count_byte >> 4) & 0xf;
result += ((count1 + previous_counts >= 16) ? 0 :
(0x1111111111111111 << 4 * (count1 + previous_counts)))
+ ((count1 + count2 + previous_counts >= 16) ? 0 :
(0x1111111111111111 << 4 * (count1 + count2 + previous_counts)));
previous_counts += count1 + count2;
}
Next, Jerome replaces most of the computation in the loop with table lookups. The right-hand side of the += expression depends on the variables count1, count2, and previous_counts, so it can be replaced by a table lookup like this:
result += mask_table[previous_counts][count2][count1];
count1 and count2 come from the same byte, so we can just use that byte as the table index: mask_table[previous_counts][count_byte]. Making the array one-dimensional instead, it's indexed as mask_table[previous_counts * 256 + count_byte]. In Jerome's code, previous_counts * 256 is called offset, and instead of doing offset += (count1 + count2) * 256, the code uses another lookup table. In the end, Jerome's code looks like this:
for (int i = 0; i < 8; i++) {
output += table3[((counts >> 8 * i) & 0xff) + offset];
offset += offsets[(counts >> 8 * i) & 0xff];
}
The loop will be unrolled, so i (and therefore 8 * i) is constant in each iteration. (counts >> 8 * i) & 0xff will only be computed once per iteration due to common subexpression elimination, and so the loop contains one fixed-amount right-shift, one bitwise and-operation, two table lookups, and three additions. That's not much work for the computer, and it turned out to be fast enough to win John's contest with good margin. Nice!
The Winning SIMD Solution
John's post says the code would be run on an Intel Core i7-4770 processor. That's a Haswell CPU, which means it supports AVX2: 256-bit wide SIMD registers and operations. With byte-size operations on such registers, the processor can operate on 32 independent values in parallel. Alexander's winning solution makes use of this capability to perform 32 nibble-sorts at the same time.
The sorting is performed using a sorting network. Sorting networks are useful in SIMD programming because they are oblivious to the data they are sorting, always performing the same operations regardless of the input values. That plays nicely with SIMD programming where one instruction is applied to multiple values. From what I understand, this also makes it a popular technique for sorting on GPUs.
There used to be a chapter on sorting networks in Introduction to Algorithms, but it seems to have been taken out for the third edition. However, the chapter is still available as a PDF from the publisher. There is also a section about sorting networks in Don Knuth's The Art of Computer Programming (Vol 3, Section 5.3.4), where we can find the sorting network used in Alexander's solution:
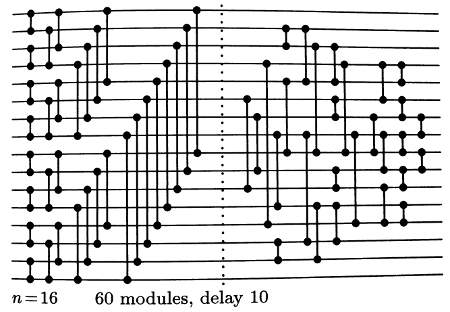
The network takes 16 inputs on the left, one on each horizontal line. At each vertical crossbar, two values are compared and potentially swapped so the largest value comes out on the lower line. After passing all the vertical crossbars, the values emerge fully sorted on the right, with the lowest value on the top line and the highest value on the bottom.
In Alexander's code, the inputs to the sorting network (from bottom to top) are called u0, u1, ..., u15. The inputs are 32-element vectors, containing the nibbles of the words being sorted. After the sorting network, u0 will contain the highest nibble for each word, u1 the second-highest, and so on.
The tedious part is getting the input data organized into the vectors the way we want it. The main loop in Alexander's code starts by reading 32 64-bit words into the 256-bit vectors u0 through u7:
for (int i = 0; i < 1024 / 4; i += 8) {
uv u0 = u[i + 0];
uv u1 = u[i + 1];
uv u2 = u[i + 2];
uv u3 = u[i + 3];
uv u4 = u[i + 4];
uv u5 = u[i + 5];
uv u6 = u[i + 6];
uv u7 = u[i + 7];
At this point, the contents of the vectors are as follows:

where

is the y'th byte of the x'th input word. To make the input suitable for the sorting network, it first needs to be transposed. Alexander does that in three steps, starting with:
tt = x32l(u0, u4);
u4 = x32h(u0, u4);
u0 = tt;
tt = x32l(u1, u5);
u5 = x32h(u1, u5);
u1 = tt;
tt = x32l(u2, u6);
u6 = x32h(u2, u6);
u2 = tt;
tt = x32l(u3, u7);
u7 = x32h(u3, u7);
u3 = tt;
x32l is a helper function that extracts the low 32-bit words from each 64-bit word in two vectors. Similarly, x32h extracts the high 32-bit words from two vectors. The code uses these to swap places between the high and low 32-bit parts of the 64-bit words. After these operations, u0..u3 contains the low 32 bits from each input word and u4..u7 contains the high bits.
The second step works at 16-bit granularity:
tt = x16l(u0, u2);
u2 = x16h(u0, u2);
u0 = tt;
tt = x16l(u1, u3);
u3 = x16h(u1, u3);
u1 = tt;
tt = x16l(u4, u6);
u6 = x16h(u4, u6);
u4 = tt;
tt = x16l(u5, u7);
u7 = x16h(u5, u7);
u5 = tt;
After this second step, u0 and u1 contain the lowest 16 bits of each input word, u2 and u3 the second lowest, and so on, with u6 and u7 containing the highest 16-bit words of each input.
The third step works at 8-bit granularity:
tt = x8l(u0, u1, m);
u1 = x8h(u0, u1, m);
u0 = tt;
tt = x8l(u2, u3, m);
u3 = x8h(u2, u3, m);
u2 = tt;
tt = x8l(u4, u5, m);
u5 = x8h(u4, u5, m);
u4 = tt;
tt = x8l(u6, u7, m);
u7 = x8h(u6, u7, m);
u6 = tt;
After the third step, u0 contains the lowest byte of each input word, u1 the second lowest, and so on, until u7 which contains the highest 8 bits of each input word. The input has now been transposed to:

Next, each byte is split into its high and low nibble:
uv u8 = (uv)(u0.u16 << 4);
uv u9 = (uv)(u1.u16 << 4);
uv u10 = (uv)(u2.u16 << 4);
uv u11 = (uv)(u3.u16 << 4);
uv u12 = (uv)(u4.u16 << 4);
uv u13 = (uv)(u5.u16 << 4);
uv u14 = (uv)(u6.u16 << 4);
uv u15 = (uv)(u7.u16 << 4);
The low nibble of each byte go into registers u8..u15. They are stored in the upper four bits. Note that they are also still available in the low bits of u0..u7, but this doesn't affect the sort as the upper bits are compared first.
Now that the inputs have been arranged, the code proceeds with the fun part, the actual sorting:
#define SWAP(a, b) \
tt = max(u##a, u##b); \
u##a = min(u##a, u##b); \
u##b = tt
SWAP(0, 1);
SWAP(2, 3);
SWAP(4, 5);
SWAP(6, 7);
SWAP(8, 9);
SWAP(10, 11);
SWAP(12, 13);
SWAP(14, 15);
SWAP(0, 2);
SWAP(4, 6);
SWAP(8, 10);
SWAP(12, 14);
SWAP(1, 3);
SWAP(5, 7);
SWAP(9, 11);
SWAP(13, 15);
SWAP(0, 4);
SWAP(8, 12);
SWAP(1, 5);
SWAP(9, 13);
SWAP(2, 6);
SWAP(10, 14);
SWAP(3, 7);
SWAP(11, 15);
SWAP(0, 8);
SWAP(1, 9);
SWAP(2, 10);
SWAP(3, 11);
SWAP(4, 12);
SWAP(5, 13);
SWAP(6, 14);
SWAP(7, 15);
SWAP(5, 10);
SWAP(6, 9);
SWAP(3, 12);
SWAP(13, 14);
SWAP(7, 11);
SWAP(1, 2);
SWAP(4, 8);
SWAP(1, 4);
SWAP(7, 13);
SWAP(2, 8);
SWAP(11, 14);
SWAP(2, 4);
SWAP(5, 6);
SWAP(9, 10);
SWAP(11, 13);
SWAP(3, 8);
SWAP(7, 12);
SWAP(6, 8);
SWAP(10, 12);
SWAP(3, 5);
SWAP(7, 9);
SWAP(3, 4);
SWAP(5, 6);
SWAP(7, 8);
SWAP(9, 10);
SWAP(11, 12);
SWAP(6, 7);
SWAP(8, 9);
The SWAP invocations act as the vertical cross-bars in the sorting network, moving the greater input to the lower output line and vice-versa.
After the sorting, u0 contains the highest nibbles, u1 the second-highest, and so on. Before we finish, the vectors need to be re-arranged for the results to be written to memory.
The first step is to merge the separate nibbles into bytes:
u0 = fold(u0, u1, mf);
u1 = fold(u2, u3, mf);
u2 = fold(u4, u5, mf);
u3 = fold(u6, u7, mf);
u4 = fold(u8, u9, mf);
u5 = fold(u10, u11, mf);
u6 = fold(u12, u13, mf);
u7 = fold(u14, u15, mf);
fold(u, v, mf) returns a vector of bytes where the high nibble in each byte comes from u and the low nibble comes from v. So after this step, u0 contains the high byte of each 64-bit word in the result we want to return, u1 the second highest, etc.
Finally, the vectors are transposed using the same procedure as before, and then written back to memory:
tt = x32l(u0, u4);
u4 = x32h(u0, u4);
u0 = tt;
tt = x32l(u1, u5);
u5 = x32h(u1, u5);
u1 = tt;
tt = x32l(u2, u6);
u6 = x32h(u2, u6);
u2 = tt;
tt = x32l(u3, u7);
u7 = x32h(u3, u7);
u3 = tt;
tt = x16l(u0, u2);
u2 = x16h(u0, u2);
u0 = tt;
tt = x16l(u1, u3);
u3 = x16h(u1, u3);
u1 = tt;
tt = x16l(u4, u6);
u6 = x16h(u4, u6);
u4 = tt;
tt = x16l(u5, u7);
u7 = x16h(u5, u7);
u5 = tt;
tt = x8l(u0, u1, m);
u1 = x8h(u0, u1, m);
u0 = tt;
tt = x8l(u2, u3, m);
u3 = x8h(u2, u3, m);
u2 = tt;
tt = x8l(u4, u5, m);
u5 = x8h(u4, u5, m);
u4 = tt;
tt = x8l(u6, u7, m);
u7 = x8h(u6, u7, m);
u6 = tt;
u[i + 0] = u0;
u[i + 1] = u1;
u[i + 2] = u2;
u[i + 3] = u3;
u[i + 4] = u4;
u[i + 5] = u5;
u[i + 6] = u6;
u[i + 7] = u7;
}
This all seems like a lot of work compared to the non-SIMD solution above, but keep in mind that the code is not just doing one nibble-sort here, but 32 of them in parallel, and there is also a lot of instruction-level parallelism. Despite all the work to transpose the data, etc., Alexander's solution runs almost eight times faster than the winning non-SIMD solution, and gets very close to sorting one word per nano-second on John's machine, which is pretty amazing.
Further Reading
- Jordan Rose provides a thorough walk-through of his non-SIMD solution
- Jethro Beekman describes his SIMD solution, also based on a sorting network.